
Tokens Are the Unit of Pain: Tokenization You Can See
Tokens are the meter your model charges in: context, latency, and cost. We'll make tokenization visible using your existing local Ollama service—first via a CLI token inspector + heatmap, then with a live-updating browser playground.
Tokens are the meter your model charges in
Tokens are where “AI vibes” go to become hard numbers. Your model does not read words, and it definitely does not read your mind, even if it occasionally pretends convincingly. It reads tokens, which means every prompt has a measurable size, every completion has a measurable size, and every latency spike has a measurable cause. When your prompt mysteriously gets cut off, or your response time balloons, tokens are usually sitting there like a raccoon next to an overturned trash can. The fastest way to build real intuition is to make tokenization visible and stop guessing.
In Part 1, we turned your local model into a boring, dependable HTTP service and measured TTFT like adults who ship software. That service boundary is still the win: we can now instrument the same runtime from tiny scripts and learn what’s actually happening. This article builds directly on that foundation by using your existing Ollama instance on http://localhost:11434. We’re going to measure prompt token counts, visualize token boundaries, and estimate latency using the numbers Ollama already gives us. Once you can see tokens, “prompt engineering” stops being mystical and starts being budgeting.
Why tokens aren’t words
Your brain thinks in words, but your model thinks in pieces of text that are convenient for compression and prediction. A token might be a whole word, a chunk of a word, a space plus a word, punctuation glued to a word, or a weird fragment you never asked for. This is why short-looking prompts can be expensive, and long-looking prompts can sometimes be cheaper than you’d expect. Tokenizers are optimized for the statistical shape of language, not for your aesthetic preferences. If you’ve ever felt personally attacked by how a model “counts,” congratulations: you have met a tokenizer.

The practical consequence is that “keep it short” is not precise advice unless you define “short” in tokens. A 500-character prompt can be tiny or massive depending on the characters involved, the whitespace patterns, and the model’s tokenizer. URLs, base64 blobs, long code identifiers, and JSON with repeated keys can explode token counts in ways that feel unfair. This is also why “just add more context” is not a free move: context competes with output inside a fixed window. The transition we’re making today is from word-count thinking to token-budget thinking, because that is how you keep systems predictable.
How tokenizers work in plain terms (BPE and unigram)
Tokenization is a compression trick wearing a developer toolbelt. Modern LLM tokenizers usually start from a simple representation (often bytes or characters) and then apply rules learned from training data to merge common sequences into single tokens. Byte Pair Encoding (BPE) does this by repeatedly merging the most frequent adjacent pairs into bigger units, which tends to create tokens for common word pieces and patterns. The result is a vocabulary that efficiently represents everyday text while still being able to fall back to smaller pieces for rare words. BPE is why “ing” or “tion” might be a token, and why a space plus “the” might also be a token. This approach is widely used in practice and is one of the reasons token boundaries can look… emotionally hostile. 3 6
Unigram tokenization (commonly associated with SentencePiece) takes a different angle: instead of merging pairs, it learns a probabilistic model over possible subword pieces and chooses a segmentation that scores well. It’s less “merge everything greedily” and more “pick the most plausible pieces from a learned set.” Both families aim for the same goal: represent text compactly in a way that makes prediction easier for the model. The model never sees your original string; it sees token IDs and learns patterns over those IDs. Once that clicks, the rest of token budgeting becomes normal engineering: measure, compare, and keep the expensive stuff out of the hot path. 4
One more truth that saves time: tokenization is model-specific. Two models can tokenize the same string differently because their vocabularies and training choices differ. Even variants of the “same” model family can behave differently if their tokenizers or chat templates differ. That’s why we’re going to measure tokens using the exact runtime and exact model you’re actually using via Ollama. When you measure with the real service, you get reality instead of folklore.
The key trick: Ollama already tells you token counts
Here’s the good news: you don’t need a separate tokenizer library to start learning. Ollama’s POST /api/generate returns prompt and generation evaluation counts and timings in its response metadata, which we can use to compute token counts and rough tokens-per-second. 1 This is not a perfect replacement for a dedicated tokenizer endpoint, but it’s stable, model-accurate, and already in the contract you’re using from Part 1. The only “cost” is that Ollama must evaluate the prompt, which is still dramatically cheaper than generating a long completion. If you set num_predict to 0, you can measure prompt tokens without spending cycles generating output.
We’re going to keep everything concrete by measuring token counts against the same local Ollama endpoint you already have running. That matters because tokenization isn’t a philosophy exercise; it’s a constraint that shows up in truncation, latency, and cost the moment you ship anything real. When token counts are invisible, prompt design turns into guesswork and superstition. When token counts are visible, you can make deliberate tradeoffs. Today we build the tools that make tokens visible.
Build: CLI that prints tokens, counts, and a “token heatmap”
This CLI does a few things that are surprisingly powerful. First, it uses your local Ollama service to count how many prompt tokens your text costs for a given model. Second, it generates a “heatmap” of token boundaries by finding where the token count increments as we extend the prompt one character at a time. That second technique is intentionally brute-force and intentionally educational, because it makes tokenization visible even when a dedicated /api/tokenize endpoint is not available. It is not fast enough for giant prompts, but it is perfect for learning because it produces a token boundary map you can stare at. You will watch your favorite strings betray you in real time.
1) Create the CLI file
Save this as token-inspector.mjs:
#!/usr/bin/env node
/**
* Token Inspector (Ollama-backed)
* - count: show raw prompt token count (as Ollama reports it), plus baseline overhead + net tokens
* - metrics: estimate prompt/generation tokens/sec from Ollama timings
* - heatmap: visual “chip” view of where token-count increments happen as you extend the prompt
* - generate: generates a response and returns usage/timing fields + response text
*
* Requires: Node 18+ (or 20+), Ollama running at http://localhost:11434
*
* Spinner:
* - Shows an npm-style spinner while the script is doing a lot of Ollama calls (especially heatmap).
* - Automatically disables for non-TTY, CI, or when using --plain / NO_COLOR.
*/
import process from 'node:process';
import { performance } from 'node:perf_hooks';
const OLLAMA = process.env.OLLAMA_URL ?? 'http://localhost:11434';
const ENDPOINT = `${OLLAMA}/api/generate`;
function usage() {
console.log(`
Token Inspector (Ollama)
Usage:
node token-inspector.mjs count --model llama3.2 --text "hello world"
node token-inspector.mjs metrics --model llama3.2 --text "hello world" --predict 128
node token-inspector.mjs heatmap --model llama3.2 --text "hello world" --max 200 [--plain] [--show-overhead]
node token-inspector.mjs generate --model llama3.2 --text "hello world" --predict 180
Notes:
- "count" shows raw tokens (Ollama-reported), baseline overhead, and net tokens.
- "metrics" estimates prompt/gen TPS from Ollama timing fields.
- "heatmap" renders colored chips in a real terminal by default.
- "generate" returns usage/timing fields plus response text.
Env:
OLLAMA_URL=http://localhost:11434
NO_COLOR=1 Disables ANSI color output
CI=1 Disables spinner output
`);
}
function parseArgs(argv) {
const out = { _: [] };
for (let i = 0; i < argv.length; i++) {
const a = argv[i];
if (a.startsWith('--')) {
const key = a.slice(2);
const val = argv[i + 1];
if (!val || val.startsWith('--')) out[key] = true;
else {
out[key] = val;
i++;
}
} else out._.push(a);
}
return out;
}
function createSpinner(initialText = 'Working…', { enabled = true } = {}) {
const isTTY = process.stderr.isTTY;
const disabledByEnv = !!process.env.CI || process.env.TERM === 'dumb';
const allow = enabled && isTTY && !disabledByEnv;
const frames = ['⠋', '⠙', '⠹', '⠸', '⠼', '⠴', '⠦', '⠧', '⠇', '⠏'];
const intervalMs = 80;
let text = initialText;
let timer = null;
let frame = 0;
function clearLine() {
process.stderr.write('\r\x1b[2K');
}
function render() {
const f = frames[frame++ % frames.length];
process.stderr.write(`\r${f} ${text}`);
}
return {
get enabled() {
return allow;
},
start(msg) {
if (!allow) return;
if (msg) text = msg;
if (timer) return;
render();
timer = setInterval(render, intervalMs);
},
update(msg) {
if (!allow) return;
text = msg;
},
stop({ ok = true, finalText } = {}) {
if (!allow) return;
if (timer) clearInterval(timer);
timer = null;
clearLine();
const symbol = ok ? '✔' : '✖';
const line = finalText ? `${symbol} ${finalText}` : '';
if (line) process.stderr.write(line + '\n');
},
fail(finalText) {
this.stop({ ok: false, finalText });
},
succeed(finalText) {
this.stop({ ok: true, finalText });
},
clear() {
if (!allow) return;
if (timer) clearInterval(timer);
timer = null;
clearLine();
},
};
}
async function postJSON(url, body) {
const res = await fetch(url, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(body),
});
if (!res.ok) throw new Error(`HTTP ${res.status}: ${await res.text()}`);
return res.json();
}
function safeSnippet(s, max = 28) {
const oneLine = s.replace(/\n/g, '\\n');
return oneLine.length > max ? oneLine.slice(0, max - 1) + '…' : oneLine;
}
const baselineCache = new Map();
/**
* Count prompt tokens as reported by Ollama (raw).
* Some Ollama builds omit prompt_eval_count when num_predict=0, so we fallback.
*/
async function countPromptTokensRaw(model, text, { allowEmpty = false } = {}) {
if (text.length === 0 && !allowEmpty) return 0;
const baseBody = {
model,
prompt: text,
stream: false,
options: { num_predict: 0 },
};
let json = await postJSON(ENDPOINT, baseBody);
if (typeof json.prompt_eval_count === 'number') return json.prompt_eval_count;
// Fallback: force minimal generation so stats show up
const retryBody = {
...baseBody,
options: { ...baseBody.options, num_predict: 1 },
};
json = await postJSON(ENDPOINT, retryBody);
if (typeof json.prompt_eval_count === 'number') return json.prompt_eval_count;
throw new Error(
`Expected prompt_eval_count in response. Got keys: ${Object.keys(json).join(', ')}`
);
}
async function getBaseline(model) {
if (baselineCache.has(model)) return baselineCache.get(model);
let baseline = 0;
try {
baseline = await countPromptTokensRaw(model, '', { allowEmpty: true });
if (typeof baseline !== 'number' || baseline < 0) baseline = 0;
} catch {
baseline = 0;
}
baselineCache.set(model, baseline);
return baseline;
}
const NO_COLOR =
!!process.env.NO_COLOR ||
process.env.TERM === 'dumb' ||
!process.stdout.isTTY;
const RESET = '\x1b[0m';
function stripAnsi(s) {
return s.replace(/\x1b\[[0-9;]*m/g, '');
}
function visibleLen(s) {
return stripAnsi(s).length;
}
function rgb(hex) {
const h = hex.replace('#', '');
const n = parseInt(h, 16);
return [(n >> 16) & 255, (n >> 8) & 255, n & 255];
}
function fg(hex) {
const [r, g, b] = rgb(hex);
return `\x1b[38;2;${r};${g};${b}m`;
}
function bg(hex) {
const [r, g, b] = rgb(hex);
return `\x1b[48;2;${r};${g};${b}m`;
}
const CHIP_BG = [
'#cb4b16',
'#b58900',
'#2aa198',
'#268bd2',
'#6c71c4',
'#859900',
'#d33682',
];
const CHIP_FG = '#fdf6e3';
function normalizeTokenText(s) {
if (s === ' ') return '␠';
if (s === '\n') return '↵';
if (s.trim() === '' && s.length > 0) return s.replace(/ /g, '␠');
return s;
}
function chip(label, text, idx) {
const bgc = CHIP_BG[idx % CHIP_BG.length];
const t = normalizeTokenText(text);
return `${bg(bgc)}${fg(CHIP_FG)} ${label}${t} ${RESET}`;
}
function wrapChips(chips, indent = ' ') {
const width = process.stdout.columns || 80;
const lines = [];
let cur = indent;
for (const c of chips) {
const add = (cur.trim().length ? ' ' : '') + c;
if (visibleLen(cur) + visibleLen(add) > width) {
lines.push(cur);
cur = indent + c;
} else {
cur += add;
}
}
if (cur.trim().length) lines.push(cur);
return lines.join('\n');
}
function hr() {
const width = process.stdout.columns || 80;
return '─'.repeat(Math.max(20, Math.min(width, 120)));
}
async function metrics(model, text, predict = 128) {
const body = {
model,
prompt: text,
stream: false,
options: { num_predict: Number(predict) },
};
const t0 = performance.now();
const json = await postJSON(ENDPOINT, body);
const t1 = performance.now();
const promptTokens = json.prompt_eval_count ?? 0;
const genTokens = json.eval_count ?? 0;
const promptNs = json.prompt_eval_duration ?? 0;
const genNs = json.eval_duration ?? 0;
const promptSec = promptNs / 1e9;
const genSec = genNs / 1e9;
const promptTps = promptSec > 0 ? promptTokens / promptSec : null;
const genTps = genSec > 0 ? genTokens / genSec : null;
return {
wallMs: t1 - t0,
promptTokens,
genTokens,
promptTps,
genTps,
raw: {
total_duration: json.total_duration,
load_duration: json.load_duration,
prompt_eval_duration: json.prompt_eval_duration,
eval_duration: json.eval_duration,
},
};
}
async function generateResponse(model, text, predict = 180) {
const body = {
model,
prompt: text,
stream: false,
options: { num_predict: Number(predict) },
};
const t0 = performance.now();
const json = await postJSON(ENDPOINT, body);
const t1 = performance.now();
return {
wallMs: t1 - t0,
json,
};
}
async function heatmap(
model,
text,
maxTokens = 200,
{ plain = false, showOverhead = false } = {}
) {
const chars = Array.from(text);
const spinner = createSpinner('Talking to Ollama…', {
enabled: !plain && !NO_COLOR && process.stdout.isTTY,
});
spinner.start('Measuring baseline + token counts…');
const baseline = await getBaseline(model);
const totalRaw = await countPromptTokensRaw(model, text, {
allowEmpty: true,
});
const totalNet = Math.max(0, totalRaw - baseline);
const limit = Math.min(totalNet, Number(maxTokens));
if (NO_COLOR || plain) {
spinner.clear();
console.log(`Model: ${model}`);
if (showOverhead) {
console.log(`Prompt tokens (raw): ${totalRaw}`);
console.log(`Baseline overhead: ${baseline}`);
console.log(`Prompt tokens (net): ${totalNet}`);
} else {
console.log(`Total prompt tokens: ${totalNet}`);
}
console.log('');
let startIdx = 0;
let prev = 0;
const segments = [];
for (let step = 0; step < limit && startIdx < chars.length; step++) {
let lo = startIdx + 1;
let hi = chars.length;
let best = null;
let bestCount = null;
if (totalNet <= prev) break;
while (lo <= hi) {
const mid = Math.floor((lo + hi) / 2);
const raw = await countPromptTokensRaw(
model,
chars.slice(0, mid).join(''),
{
allowEmpty: true,
}
);
const c = Math.max(0, raw - baseline);
if (c > prev) {
best = mid;
bestCount = c;
hi = mid - 1;
} else {
lo = mid + 1;
}
}
if (best === null) break;
const seg = chars.slice(startIdx, best).join('');
const delta = bestCount - prev;
segments.push({ seg, delta });
startIdx = best;
prev = bestCount;
}
if (startIdx < chars.length) {
segments.push({ seg: chars.slice(startIdx).join(''), delta: 0 });
}
let out = '';
let tokenIdx = 0;
segments.forEach(s => {
const label =
s.delta === 0
? '(tail)'
: s.delta === 1
? `${tokenIdx}`
: `${tokenIdx}..${tokenIdx + s.delta - 1}`;
out += `[${label}:${safeSnippet(s.seg, 24)}]`;
if (s.delta > 0) tokenIdx += s.delta;
});
console.log(out);
console.log(
'\nLegend: [index:(fragment)] where (tail) means 0 new tokens; it extended the last token.\n'
);
return;
}
let startIdx = 0;
let prevCount = 0;
const segments = [];
let calls = 0;
async function countNetPrefix(mid) {
calls += 1;
const raw = await countPromptTokensRaw(
model,
chars.slice(0, mid).join(''),
{ allowEmpty: true }
);
return Math.max(0, raw - baseline);
}
for (let step = 0; step < limit && startIdx < chars.length; step++) {
spinner.update(`Mapping tokens… ${prevCount}/${limit} (calls: ${calls})`);
let lo = startIdx + 1;
let hi = chars.length;
let best = null;
let bestCount = null;
if (totalNet <= prevCount) break;
while (lo <= hi) {
const mid = Math.floor((lo + hi) / 2);
const c = await countNetPrefix(mid);
if (c > prevCount) {
best = mid;
bestCount = c;
hi = mid - 1;
} else {
lo = mid + 1;
}
}
if (best === null) break;
const seg = chars.slice(startIdx, best).join('');
const delta = bestCount - prevCount;
segments.push({ seg, delta });
startIdx = best;
prevCount = bestCount;
}
if (startIdx < chars.length) {
segments.push({ seg: chars.slice(startIdx).join(''), delta: 0 });
}
spinner.succeed(`Heatmap ready (${calls} Ollama calls).`);
console.log(hr());
console.log(`Model: ${model}`);
if (showOverhead) {
console.log(`Prompt tokens (raw): ${totalRaw}`);
console.log(`Baseline overhead: ${baseline}`);
console.log(`Prompt tokens (net): ${totalNet}`);
} else {
console.log(`Total prompt tokens: ${totalNet}`);
}
console.log('');
let tokenIndex = 0;
const chips = segments.map((s, i) => {
let label;
if (s.delta === 0) {
label = '[tail:';
} else if (s.delta === 1) {
label = `[${tokenIndex}:`;
tokenIndex += 1;
} else {
const start = tokenIndex;
const end = tokenIndex + s.delta - 1;
label = `[${start}..${end}:`;
tokenIndex += s.delta;
}
return chip(label, safeSnippet(s.seg, 40) + ']', i);
});
console.log('');
console.log('→ ' + wrapChips(chips, ' '));
console.log('');
console.log('Pairs get merged in steps to form larger pieces.');
console.log('(use NO_COLOR=1 or --plain for log-friendly output)');
console.log(hr());
console.log('');
}
async function main() {
const argv = process.argv.slice(2);
const cmd = argv[0];
const args = parseArgs(argv.slice(1));
if (!cmd || args.help) {
usage();
process.exit(0);
}
const model = args.model ?? 'llama3.2';
const text = args.text ?? '';
if (!text) {
console.error('Missing --text');
usage();
process.exit(1);
}
if (cmd === 'count') {
const spinner = createSpinner('Counting…', {
enabled: process.stdout.isTTY && !NO_COLOR,
});
spinner.start('Counting tokens…');
const baseline = await getBaseline(model);
const raw = await countPromptTokensRaw(model, text, { allowEmpty: true });
const net = Math.max(0, raw - baseline);
spinner.succeed('Count complete.');
console.log(`Model: ${model}`);
console.log(`Prompt tokens (raw): ${raw}`);
console.log(`Baseline overhead: ${baseline}`);
console.log(`Prompt tokens (net): ${net}`);
console.log(`Chars: ${Array.from(text).length}`);
console.log(`Preview: ${safeSnippet(text, 80)}`);
return;
}
if (cmd === 'metrics') {
const predict = args.predict ?? '128';
const spinner = createSpinner('Measuring…', {
enabled: process.stdout.isTTY && !NO_COLOR,
});
spinner.start('Measuring latency + TPS…');
const m = await metrics(model, text, predict);
spinner.succeed('Metrics complete.');
console.log(`Model: ${model}`);
console.log(`Prompt tokens: ${m.promptTokens}`);
console.log(`Gen tokens: ${m.genTokens}`);
console.log(
`Prompt TPS: ${m.promptTps ? m.promptTps.toFixed(1) : 'n/a'}`
);
console.log(`Gen TPS: ${m.genTps ? m.genTps.toFixed(1) : 'n/a'}`);
console.log(`Wall time: ${m.wallMs.toFixed(0)} ms`);
return;
}
if (cmd === 'generate') {
const predict = args.predict ?? '180';
const spinner = createSpinner('Generating…', {
enabled: process.stdout.isTTY && !NO_COLOR,
});
spinner.start('Generating response…');
const result = await generateResponse(model, text, predict);
spinner.succeed('Generate complete.');
const json = result.json || {};
const promptTokens = json.prompt_eval_count ?? 0;
const genTokens = json.eval_count ?? 0;
const promptMs = json.prompt_eval_duration
? json.prompt_eval_duration / 1e6
: null;
const genMs = json.eval_duration ? json.eval_duration / 1e6 : null;
const totalMs = json.total_duration ? json.total_duration / 1e6 : null;
console.log(`Model: ${model}`);
console.log(`Prompt tokens: ${promptTokens}`);
console.log(`Gen tokens: ${genTokens}`);
if (promptMs !== null) {
console.log(`Prompt eval: ${promptMs.toFixed(1)} ms`);
}
if (genMs !== null) {
console.log(`Gen eval: ${genMs.toFixed(1)} ms`);
}
if (totalMs !== null) {
console.log(`Total: ${totalMs.toFixed(1)} ms`);
}
console.log(`Wall time: ${result.wallMs.toFixed(0)} ms`);
console.log('');
console.log(json.response ?? '(No response returned)');
return;
}
if (cmd === 'heatmap') {
const max = args.max ?? '200';
const plain = !!args.plain;
const showOverhead = !!args['show-overhead'];
await heatmap(model, text, Number(max), { plain, showOverhead });
return;
}
console.error(`Unknown command: ${cmd}`);
usage();
process.exit(1);
}
main().catch(err => {
console.error(err.stack || err.message || String(err));
process.exit(1);
});
2) Run it against your existing local service
First, confirm Ollama is running (from Part 1) and that you have llama3.2 pulled. Then try these commands:
node token-inspector.mjs count --model llama3.2 --text "Hello, tokens."
node token-inspector.mjs heatmap --model llama3.2 --text "Hello, tokens."
node token-inspector.mjs metrics --model llama3.2 --text "Explain tokenization in a practical paragraph." --predict 128
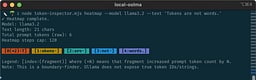
The heatmap output is where the learning gets visceral. You will see that spaces often “stick” to the next token, punctuation sometimes glues itself onto a neighbor, and weird fragments appear when the tokenizer prefers a different segmentation than your human brain. When the heatmap shows a (+2) or (+3) fragment, that is your model quietly telling you that a single character forced multiple token pieces. If you’ve ever wondered why a prompt with emojis or URLs feels heavier, this is one of the ways that weight leaks into the system. The transition here is simple: you are no longer arguing about prompt length; you are measuring it.
Build: a local web page that live-updates token counts as you type
A browser playground is the fastest way to build intuition because you can watch token counts change as you edit a prompt. The annoying obstacle is browser security: your static page may not be allowed to call http://localhost:11434 directly due to CORS and mixed-content rules, depending on how you serve it. Instead of fighting that battle in every reader’s environment, we’re going to do the practical thing: run a tiny local server that serves the page and proxies token counting to Ollama. This keeps everything local, keeps the learning loop fast, and avoids “works on my browser” arguments.

1) Create the local playground server
Save this as tokenizer-playground-server.mjs:
#!/usr/bin/env node
/**
* Tokenizer Playground Server (Ollama-backed)
* - Serves a local page at http://127.0.0.1:8787
* - /models => lists local Ollama model tags
* - /count => prompt token count via /api/generate usage fields (prompt_eval_count)
* - /metrics => prompt/gen tokens/sec from Ollama timing fields
* - /heatmap => educational boundary finder that renders a "token heatmap"
* - /generate => generates a response and returns usage/timing fields + response text
*
* Notes:
* - raw:true counts *your text*, not a chat template wrapper.
* - num_predict:1 forces usage metrics to be emitted on some builds that omit them for 0.
*
* Requires: Node 18+ (global fetch)
*/
import http from 'node:http';
import { URL } from 'node:url';
import { performance } from 'node:perf_hooks';
const HOST = process.env.HOST ?? '127.0.0.1';
const PORT = Number(process.env.PORT ?? 8787);
const OLLAMA = (process.env.OLLAMA_URL ?? 'http://127.0.0.1:11434').replace(
/\/+$/,
''
);
const endpoints = {
generate: `${OLLAMA}/api/generate`,
tags: `${OLLAMA}/api/tags`,
};
const send = (res, code, body, type = 'text/plain; charset=utf-8') => {
res.writeHead(code, { 'Content-Type': type, 'Cache-Control': 'no-store' });
res.end(body);
};
const sendJSON = (res, code, obj) =>
send(res, code, JSON.stringify(obj), 'application/json; charset=utf-8');
const safeError = e => {
const msg = String(e?.message ?? e ?? 'Unknown error');
return msg.length > 1200 ? msg.slice(0, 1200) + '…' : msg;
};
const readJSON = async req => {
const chunks = [];
for await (const c of req) chunks.push(c);
const raw = Buffer.concat(chunks).toString('utf-8');
if (!raw.trim()) return {};
try {
return JSON.parse(raw);
} catch {
throw new Error('Invalid JSON body');
}
};
const fetchText = async (url, opts) => {
const r = await fetch(url, opts);
const text = await r.text();
if (!r.ok)
throw new Error(`Upstream HTTP ${r.status}: ${text.slice(0, 500)}`);
return text;
};
const getJSON = async url =>
JSON.parse(await fetchText(url, { method: 'GET' }));
const postJSON = async (url, body) =>
JSON.parse(
await fetchText(url, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(body),
})
);
const clampInt = (n, fallback, min, max) => {
const x = Number.parseInt(String(n ?? ''), 10);
if (!Number.isFinite(x)) return fallback;
return Math.max(min, Math.min(max, x));
};
/**
* Count prompt tokens using Ollama usage metrics.
* Uses num_predict:1 to force usage metrics on some builds.
*/
const countPromptTokens = async (model, text) => {
const json = await postJSON(endpoints.generate, {
model,
prompt: text,
stream: false,
raw: true,
options: { num_predict: 1 },
});
const n = json?.prompt_eval_count;
if (typeof n !== 'number') {
throw new Error(
`Missing prompt_eval_count from Ollama response. Keys: ${
json && typeof json === 'object'
? Object.keys(json).join(', ')
: '(non-object)'
}`
);
}
return n;
};
/**
* Metrics: estimate prompt/gen tokens per second.
* Uses Ollama timing fields (durations in nanoseconds).
*/
const measureMetrics = async (model, text, predict = 128) => {
const body = {
model,
prompt: text,
stream: false,
raw: true,
options: { num_predict: Number(predict) },
};
const t0 = performance.now();
const json = await postJSON(endpoints.generate, body);
const t1 = performance.now();
const promptTokens =
typeof json.prompt_eval_count === 'number' ? json.prompt_eval_count : 0;
const genTokens = typeof json.eval_count === 'number' ? json.eval_count : 0;
const promptNs =
typeof json.prompt_eval_duration === 'number'
? json.prompt_eval_duration
: 0;
const genNs = typeof json.eval_duration === 'number' ? json.eval_duration : 0;
const promptSec = promptNs / 1e9;
const genSec = genNs / 1e9;
const promptTps = promptSec > 0 ? promptTokens / promptSec : null;
const genTps = genSec > 0 ? genTokens / genSec : null;
return {
wallMs: t1 - t0,
promptTokens,
genTokens,
promptTps,
genTps,
raw: {
total_duration: json.total_duration,
load_duration: json.load_duration,
prompt_eval_duration: json.prompt_eval_duration,
eval_duration: json.eval_duration,
},
};
};
/**
* Generate: returns response text + usage/timing fields.
*/
const generateResponse = async (model, text, predict = 180) => {
const body = {
model,
prompt: text,
stream: false,
raw: true,
options: { num_predict: Number(predict) },
};
const t0 = performance.now();
const json = await postJSON(endpoints.generate, body);
const t1 = performance.now();
const response = typeof json?.response === 'string' ? json.response : '';
const promptTokens =
typeof json.prompt_eval_count === 'number' ? json.prompt_eval_count : 0;
const genTokens = typeof json.eval_count === 'number' ? json.eval_count : 0;
const promptNs =
typeof json.prompt_eval_duration === 'number'
? json.prompt_eval_duration
: 0;
const genNs = typeof json.eval_duration === 'number' ? json.eval_duration : 0;
const promptSec = promptNs / 1e9;
const genSec = genNs / 1e9;
const promptTps = promptSec > 0 ? promptTokens / promptSec : null;
const genTps = genSec > 0 ? genTokens / genSec : null;
return {
wallMs: t1 - t0,
promptTokens,
genTokens,
promptTps,
genTps,
response,
raw: {
total_duration: json.total_duration,
load_duration: json.load_duration,
prompt_eval_duration: json.prompt_eval_duration,
eval_duration: json.eval_duration,
done: json.done,
done_reason: json.done_reason,
},
};
};
/**
* Heatmap:
* Finds segments of the prompt where the *prompt token count* increases.
*/
const buildHeatmap = async (model, text, maxSteps = 120) => {
const chars = Array.from(text);
const fullText = chars.join('');
const totalTokens = await countPromptTokens(model, fullText);
const limit = Math.max(1, Math.min(Number(maxSteps) || 120, totalTokens));
const memo = new Map(); // prefixLen -> promptTokens
const countPrefix = async prefixLen => {
if (memo.has(prefixLen)) return memo.get(prefixLen);
const prefix = chars.slice(0, prefixLen).join('');
const n = prefixLen === 0 ? 0 : await countPromptTokens(model, prefix);
memo.set(prefixLen, n);
return n;
};
let startIdx = 0;
let prevCount = await countPrefix(0);
const segments = [];
for (let step = 0; step < limit && startIdx < chars.length; step++) {
const fullPrefixCount = await countPrefix(chars.length);
if (fullPrefixCount <= prevCount) break;
let lo = startIdx + 1;
let hi = chars.length;
let best = null;
let bestCount = null;
while (lo <= hi) {
const mid = Math.floor((lo + hi) / 2);
const c = await countPrefix(mid);
if (c > prevCount) {
best = mid;
bestCount = c;
hi = mid - 1;
} else {
lo = mid + 1;
}
}
if (best === null) break;
const seg = chars.slice(startIdx, best).join('');
const delta = bestCount - prevCount;
segments.push({ seg, delta });
startIdx = best;
prevCount = bestCount;
}
const remainder =
startIdx < chars.length ? chars.slice(startIdx).join('') : '';
return {
model,
textLen: chars.length,
totalTokens,
limit,
segments,
remainder,
};
};
const html = `<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width,initial-scale=1" />
<title>Tokenizer Playground</title>
<style>
:root{
--base03:#002b36;
--base02:#073642;
--base01:#586e75;
--base00:#657b83;
--base0:#839496;
--base1:#93a1a1;
--base2:#eee8d5;
--base3:#fdf6e3;
--yellow:#b58900;
--orange:#cb4b16;
--red:#dc322f;
--magenta:#d33682;
--violet:#6c71c4;
--blue:#268bd2;
--cyan:#2aa198;
--green:#859900;
--shadow: 0 18px 55px rgba(0,0,0,.18);
--radius: 14px;
}
* { box-sizing: border-box; }
body{
margin:0;
min-height:100vh;
display:grid;
place-items:center;
padding: 24px;
background:
radial-gradient(1100px 520px at 45% 18%, rgba(42,161,152,.12), transparent 60%),
radial-gradient(900px 420px at 20% 22%, rgba(38,139,210,.10), transparent 55%),
linear-gradient(180deg, rgba(0,0,0,.03), rgba(0,0,0,0)),
var(--base3);
color: var(--base02);
font-family: ui-monospace, "JetBrains Mono", SFMono-Regular, Menlo, Monaco, Consolas, "Liberation Mono", "Courier New", monospace;
}
.window{
width: min(1040px, 100%);
border-radius: var(--radius);
overflow:hidden;
box-shadow: var(--shadow);
border: 1px solid rgba(7,54,66,.18);
background: var(--base3);
}
.titlebar{
padding: 18px 22px;
font-size: 34px;
font-weight: 900;
letter-spacing: .2px;
color: var(--base02);
background:
linear-gradient(180deg, rgba(255,255,255,.60), rgba(255,255,255,.20)),
var(--base2);
border-bottom: 1px solid rgba(7,54,66,.14);
}
.content{
padding: 18px;
background:
radial-gradient(900px 340px at 30% 8%, rgba(7,54,66,.05), transparent 60%),
var(--base3);
}
.panel{
border-radius: 12px;
border: 1px solid rgba(7,54,66,.14);
background: rgba(255,255,255,.55);
padding: 14px;
}
.grid{
display:grid;
grid-template-columns: 1fr 340px;
gap: 14px;
align-items: stretch;
}
@media (max-width: 920px){
.grid{ grid-template-columns: 1fr; }
}
.label{
font-size: 18px;
font-weight: 900;
margin: 0 0 10px;
color: var(--base02);
}
textarea{
width: 100%;
min-height: 270px;
resize: vertical;
padding: 16px;
font-size: 22px;
line-height: 1.35;
color: var(--base02);
border-radius: 10px;
border: 1px solid rgba(7,54,66,.22);
background: rgba(255,255,255,.70);
outline: none;
box-shadow: inset 0 0 0 1px rgba(0,0,0,.03);
}
textarea:focus{
border-color: rgba(38,139,210,.70);
box-shadow: 0 0 0 3px rgba(38,139,210,.18);
}
textarea:disabled{
opacity: .75;
cursor: not-allowed;
background: rgba(238,232,213,.55);
}
.stats{
display:flex;
flex-direction:column;
gap: 12px;
padding: 8px 10px;
border-left: 1px solid rgba(7,54,66,.12);
}
@media (max-width: 920px){
.stats{ border-left: none; border-top: 1px solid rgba(7,54,66,.12); padding-top: 14px; }
}
.statline{
display:flex;
align-items:center;
justify-content:space-between;
gap: 10px;
padding: 8px 0;
border-bottom: 1px solid rgba(7,54,66,.10);
}
.statline:last-child{ border-bottom:none; }
.statkey{
color: var(--base01);
font-size: 16px;
font-weight: 800;
}
.badge{
display:inline-flex;
align-items:center;
justify-content:center;
min-width: 42px;
height: 32px;
padding: 0 10px;
border-radius: 9px;
font-size: 18px;
font-weight: 900;
color: var(--base02);
background: rgba(181,137,0,.18);
border: 1px solid rgba(181,137,0,.40);
}
.value{
color: var(--base02);
font-size: 16px;
font-weight: 900;
text-align:right;
}
.subtle{
color: var(--base01);
font-size: 13px;
line-height: 1.35;
margin-top: 2px;
}
.miniGrid{
display:grid;
grid-template-columns: 1fr 1fr;
gap: 10px 14px;
margin-top: 6px;
}
@media (max-width: 920px){
.miniGrid{ grid-template-columns: 1fr; }
}
.mini{
padding: 8px 0;
border-bottom: 1px solid rgba(7,54,66,.08);
display:flex;
justify-content:space-between;
gap: 10px;
font-size: 14px;
color: var(--base02);
}
.mini:last-child{ border-bottom:none; }
.mini b{ font-weight: 900; }
.footer{
display:flex;
align-items:center;
justify-content:space-between;
gap: 12px;
margin-top: 14px;
flex-wrap:wrap;
padding-top: 12px;
border-top: 1px solid rgba(7,54,66,.12);
}
.row{
display:flex;
align-items:center;
gap: 12px;
flex-wrap:wrap;
}
select, input{
font: inherit;
font-size: 16px;
color: var(--base02);
background: rgba(255,255,255,.70);
border: 1px solid rgba(7,54,66,.22);
border-radius: 10px;
padding: 10px 12px;
outline: none;
}
select:focus, input:focus{
border-color: rgba(38,139,210,.70);
box-shadow: 0 0 0 3px rgba(38,139,210,.18);
}
input:disabled, select:disabled{
opacity:.75;
cursor:not-allowed;
background: rgba(238,232,213,.55);
}
button{
font: inherit;
font-size: 15px;
padding: 11px 14px;
border-radius: 12px;
border: 1px solid rgba(7,54,66,.20);
background: rgba(255,255,255,.60);
color: var(--base02);
cursor: pointer;
transition: filter 120ms ease, transform 120ms ease, border-color 120ms ease;
display:inline-flex;
align-items:center;
gap: 10px;
font-weight: 900;
}
button:hover{ filter: brightness(1.03); border-color: rgba(7,54,66,.32); }
button:active{ transform: translateY(1px); filter: brightness(0.98); }
button:disabled{
opacity: .55;
cursor: not-allowed;
transform: none;
filter: none;
}
button.primary{
background: rgba(38,139,210,.22);
border-color: rgba(38,139,210,.55);
box-shadow: 0 10px 26px rgba(38,139,210,.12);
}
button.primary:hover{ background: rgba(38,139,210,.28); border-color: rgba(38,139,210,.75); }
.statusPill{
display:inline-flex;
align-items:center;
gap: 10px;
padding: 9px 12px;
border-radius: 999px;
border: 1px solid rgba(7,54,66,.18);
background: rgba(255,255,255,.55);
color: var(--base02);
font-size: 13px;
user-select:none;
white-space:nowrap;
font-weight: 900;
}
.dot{
width: 10px; height: 10px;
border-radius: 999px;
background: rgba(147,161,161,.85);
box-shadow: 0 0 0 2px rgba(0,43,54,.08);
}
.dot.ok{ background: rgba(133,153,0,.95); }
.dot.bad{ background: rgba(220,50,47,.95); }
.dot.busy{
background: rgba(181,137,0,.95);
animation: pulse 900ms ease-in-out infinite;
}
@keyframes pulse{
0%,100%{ transform: scale(1); opacity: .85; }
50%{ transform: scale(1.25); opacity: 1; }
}
.spinner{
width: 14px;
height: 14px;
border-radius: 999px;
border: 2px solid rgba(88,110,117,.35);
border-top-color: rgba(7,54,66,.85);
animation: spin .75s linear infinite;
}
@keyframes spin { to { transform: rotate(360deg); } }
.err{
display:none;
margin-top: 12px;
padding: 10px 12px;
border-radius: 12px;
background: rgba(220,50,47,.10);
border: 1px solid rgba(220,50,47,.26);
color: var(--base02);
font-size: 13px;
white-space: pre-wrap;
}
.err.show{ display:block; }
.below{
margin-top: 14px;
border-top: 1px solid rgba(7,54,66,.12);
padding-top: 14px;
display:grid;
grid-template-columns: 1fr;
gap: 12px;
}
.heatmapWrap{
border-radius: 12px;
border: 1px solid rgba(7,54,66,.14);
background: rgba(255,255,255,.55);
padding: 12px;
overflow:auto;
}
.tokRow{
display:flex;
flex-wrap:wrap;
gap: 8px;
padding: 2px 2px 6px;
}
.tok{
display:inline-flex;
align-items:center;
padding: 8px 10px;
border-radius: 10px;
border: 1px solid rgba(7,54,66,.14);
color: var(--base02);
background: rgba(181,137,0,.14);
font-size: 15px;
white-space: pre;
font-weight: 800;
}
.c0{ background: rgba(203,75,22,.14); border-color: rgba(203,75,22,.26); }
.c1{ background: rgba(181,137,0,.14); border-color: rgba(181,137,0,.26); }
.c2{ background: rgba(42,161,152,.14); border-color: rgba(42,161,152,.26); }
.c3{ background: rgba(38,139,210,.14); border-color: rgba(38,139,210,.26); }
.c4{ background: rgba(108,113,196,.14); border-color: rgba(108,113,196,.26); }
.c5{ background: rgba(211,54,130,.14); border-color: rgba(211,54,130,.26); }
.c6{ background: rgba(133,153,0,.14); border-color: rgba(133,153,0,.26); }
.c7{ background: rgba(220,50,47,.14); border-color: rgba(220,50,47,.26); }
.remainder{
background: rgba(88,110,117,.10);
border-color: rgba(88,110,117,.20);
}
.legend{
color: var(--base01);
font-size: 13px;
line-height: 1.35;
padding: 6px 2px 0;
}
.responseBox{
border-radius: 12px;
border: 1px solid rgba(7,54,66,.14);
background: rgba(255,255,255,.55);
padding: 12px;
overflow:auto;
}
.responseText{
margin:0;
padding: 0;
white-space: pre-wrap;
line-height: 1.45;
font-size: 15px;
color: var(--base02);
font-weight: 700;
}
.responseMeta{
margin-top: 10px;
padding-top: 10px;
border-top: 1px solid rgba(7,54,66,.10);
font-size: 12px;
color: var(--base01);
display:flex;
gap: 12px;
flex-wrap:wrap;
}
.chip{
border: 1px solid rgba(7,54,66,.14);
background: rgba(238,232,213,.35);
border-radius: 999px;
padding: 6px 10px;
font-weight: 900;
}
</style>
</head>
<body>
<div class="window">
<div class="titlebar">Tokenizer Playground</div>
<div class="content">
<div class="panel">
<div class="grid">
<div>
<div class="label" for="text">Prompt:</div>
<textarea id="text" placeholder="Type a prompt..."></textarea>
<div class="footer">
<div class="row">
<div style="font-weight:900;">Model:</div>
<select id="model"></select>
</div>
<div class="row">
<div style="font-weight:900;">Predict:</div>
<input id="predict" value="180" inputmode="numeric" style="width:96px" />
</div>
<div class="row">
<div style="font-weight:900;">Heatmap steps:</div>
<input id="maxSteps" value="120" inputmode="numeric" style="width:96px" />
</div>
<div class="row">
<button class="primary" id="analyze">
<span id="analyzeSpinner" class="spinner" style="display:none;"></span>
<span id="analyzeLabel">Analyze</span>
</button>
<span class="statusPill" title="Shows whether the last request succeeded">
<span class="dot" id="dot"></span>
<span id="status">idle</span>
</span>
</div>
</div>
<div class="err" id="err"></div>
</div>
<div class="stats">
<div class="statline">
<div class="statkey">Prompt tokens:</div>
<div class="badge" id="tokens">—</div>
</div>
<div class="statline">
<div class="statkey">Model:</div>
<div class="value" id="modelLabel">—</div>
</div>
<div class="statline">
<div class="statkey">Chars:</div>
<div class="value" id="chars">—</div>
</div>
<div class="subtle">Metrics (auto as you type):</div>
<div class="miniGrid">
<div class="mini"><span>Prompt TPS</span><b id="promptTps">—</b></div>
<div class="mini"><span>Gen TPS</span><b id="genTps">—</b></div>
<div class="mini"><span>Gen tokens</span><b id="genTokens">—</b></div>
<div class="mini"><span>Wall time</span><b id="wallMs">—</b></div>
</div>
<div class="subtle">
<p>Count + metrics update while you type (debounced).</p>
<p>Analyze runs: count, metrics, heatmap, and a real generation.</p>
<p>The UI locks during Analyze so results match the exact prompt.</p>
</div>
</div>
</div>
<div class="below">
<div>
<div class="label" style="margin:0 0 10px;">Heatmap:</div>
<div class="heatmapWrap">
<div class="tokRow" id="heatmapTokens"></div>
<div class="legend" id="heatLegend"></div>
</div>
</div>
<div>
<div class="label" style="margin:0 0 10px;">Response:</div>
<div class="responseBox">
<pre class="responseText" id="responseText">(Run Analyze to generate a response.)</pre>
<div class="responseMeta" id="responseMeta" style="display:none;"></div>
</div>
</div>
</div>
</div>
</div>
</div>
<script>
const el = (id) => document.getElementById(id);
const textEl = el('text');
const modelSelect = el('model');
const modelLabel = el('modelLabel');
const tokensEl = el('tokens');
const charsEl = el('chars');
const promptTpsEl = el('promptTps');
const genTpsEl = el('genTps');
const genTokensEl = el('genTokens');
const wallMsEl = el('wallMs');
const predictEl = el('predict');
const maxStepsEl = el('maxSteps');
const heatmapTokensEl = el('heatmapTokens');
const heatLegendEl = el('heatLegend');
const responseTextEl = el('responseText');
const responseMetaEl = el('responseMeta');
const analyzeBtn = el('analyze');
const analyzeSpinner = el('analyzeSpinner');
const analyzeLabel = el('analyzeLabel');
const statusEl = el('status');
const dotEl = el('dot');
const errEl = el('err');
let debounceTimer = null;
let autoAbort = null;
let locked = false;
const setStatus = (kind, msg) => {
statusEl.textContent = msg;
dotEl.className = 'dot ' + (kind || '');
};
const setError = (msg) => {
if (!msg) {
errEl.classList.remove('show');
errEl.textContent = '';
return;
}
errEl.classList.add('show');
errEl.textContent = msg;
};
const isBlank = (s) => !String(s ?? '').trim();
const fmt = (n, digits = 1) => {
if (n === null || n === undefined) return '—';
if (typeof n !== 'number' || Number.isNaN(n)) return '—';
return n.toFixed(digits);
};
const clampInt = (value, fallback, min, max) => {
const n = Number.parseInt(String(value ?? ''), 10);
if (!Number.isFinite(n)) return fallback;
return Math.max(min, Math.min(max, n));
};
const setLocked = (on) => {
locked = !!on;
textEl.disabled = locked;
modelSelect.disabled = locked;
predictEl.disabled = locked;
maxStepsEl.disabled = locked;
analyzeBtn.disabled = locked || isBlank(textEl.value);
analyzeSpinner.style.display = locked ? '' : 'none';
analyzeLabel.textContent = locked ? 'Analyzing…' : 'Analyze';
};
const clearHeatmap = () => {
heatmapTokensEl.innerHTML = '';
heatLegendEl.textContent = '';
};
const clearResponse = () => {
responseTextEl.textContent = '(Run Analyze to generate a response.)';
responseMetaEl.style.display = 'none';
responseMetaEl.innerHTML = '';
};
const renderResponse = (data) => {
const response = String(data?.response ?? '').trim();
responseTextEl.textContent = response || '(no response text returned)';
const chips = [];
const addChip = (k, v) => chips.push('<span class="chip">' + k + ': ' + v + '</span>');
addChip('genTokens', (typeof data?.genTokens === 'number') ? String(data.genTokens) : '—');
addChip('genTPS', data?.genTps ? fmt(data.genTps, 1) : '—');
addChip('wall', (typeof data?.wallMs === 'number') ? (data.wallMs.toFixed(0) + 'ms') : '—');
responseMetaEl.innerHTML = chips.join('');
responseMetaEl.style.display = '';
};
const renderHeatmap = (data) => {
heatmapTokensEl.innerHTML = '';
const segs = Array.isArray(data?.segments) ? data.segments : [];
segs.forEach((s, i) => {
const span = document.createElement('span');
span.className = 'tok c' + (i % 8);
const raw = String(s.seg ?? '');
const shown = raw
.replaceAll(' ', '␠')
.replaceAll('\\u00A0', '⍽')
.replaceAll('\\u00a0', '⍽')
.replaceAll('\\n', '\\\\n')
.replaceAll('\\t', '\\\\t')
.replaceAll('\\r', '\\\\r');
const delta = Number(s.delta ?? 1);
const label = delta === 1 ? '' : '(+' + delta + ')';
span.textContent = '[' + i + label + ':' + shown + ']';
heatmapTokensEl.appendChild(span);
});
const remainder = String(data?.remainder ?? '');
if (remainder) {
const span = document.createElement('span');
span.className = 'tok remainder';
span.textContent =
'[…:' +
remainder
.replaceAll(' ', '␠')
.replaceAll('\\u00A0', '⍽')
.replaceAll('\\u00a0', '⍽')
.replaceAll('\\n', '\\\\n')
.replaceAll('\\t', '\\\\t')
.replaceAll('\\r', '\\\\r') +
']';
heatmapTokensEl.appendChild(span);
}
const total = data?.totalTokens ?? '—';
const limit = data?.limit ?? '—';
const textLen = data?.textLen ?? '—';
heatLegendEl.textContent =
'Legend: [index:(fragment)] where (+N) means that fragment increased prompt token count by N. ' +
'Model prompt tokens: ' + total + '. Heatmap steps cap: ' + limit + '. Text length: ' + textLen + ' chars.';
};
const loadModels = async () => {
try {
const res = await fetch('/models');
const json = await res.json();
const models = Array.isArray(json?.models) ? json.models : [];
modelSelect.innerHTML = '';
const fallback = 'llama3.2';
const preferred = models.includes(fallback) ? fallback : (models[0] || fallback);
const list = models.length ? models : [fallback];
list.forEach((name) => {
const opt = document.createElement('option');
opt.value = name;
opt.textContent = name;
modelSelect.appendChild(opt);
});
modelSelect.value = preferred;
modelLabel.textContent = preferred;
} catch {
modelSelect.innerHTML = '';
const opt = document.createElement('option');
opt.value = 'llama3.2';
opt.textContent = 'llama3.2';
modelSelect.appendChild(opt);
modelSelect.value = 'llama3.2';
modelLabel.textContent = 'llama3.2';
}
};
const updateBasics = () => {
const text = textEl.value ?? '';
charsEl.textContent = String(Array.from(text).length);
modelLabel.textContent = modelSelect.value || 'llama3.2';
analyzeBtn.disabled = locked || isBlank(text);
};
const clearMetrics = () => {
promptTpsEl.textContent = '—';
genTpsEl.textContent = '—';
genTokensEl.textContent = '—';
wallMsEl.textContent = '—';
};
const clearCount = () => {
tokensEl.textContent = '—';
};
const abortAuto = () => {
if (autoAbort) autoAbort.abort();
autoAbort = null;
};
const autoUpdate = async () => {
if (locked) return;
const text = textEl.value ?? '';
const model = modelSelect.value || 'llama3.2';
updateBasics();
if (isBlank(text)) {
abortAuto();
setError('');
setStatus('', 'idle');
clearCount();
clearMetrics();
clearHeatmap();
clearResponse();
return;
}
abortAuto();
autoAbort = new AbortController();
const signal = autoAbort.signal;
setError('');
setStatus('busy', 'working…');
try {
const countRes = await fetch('/count', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
signal,
body: JSON.stringify({ model, text }),
});
const countJson = await countRes.json();
if (!countRes.ok) throw new Error(countJson?.error || 'Count failed');
tokensEl.textContent = String(countJson.promptTokens);
const predict = 32;
const mRes = await fetch('/metrics', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
signal,
body: JSON.stringify({ model, text, predict }),
});
const mJson = await mRes.json();
if (!mRes.ok) throw new Error(mJson?.error || 'Metrics failed');
promptTpsEl.textContent = mJson.promptTps ? fmt(mJson.promptTps, 1) : '—';
genTpsEl.textContent = mJson.genTps ? fmt(mJson.genTps, 1) : '—';
genTokensEl.textContent = typeof mJson.genTokens === 'number' ? String(mJson.genTokens) : '—';
wallMsEl.textContent = typeof mJson.wallMs === 'number' ? (mJson.wallMs.toFixed(0) + ' ms') : '—';
if (typeof mJson.promptTokens === 'number') {
tokensEl.textContent = String(mJson.promptTokens);
}
setStatus('ok', 'ok');
} catch (e) {
if (String(e?.name) === 'AbortError') return;
setStatus('bad', 'error');
setError(String(e?.message ?? e));
clearCount();
clearMetrics();
}
};
const scheduleAuto = () => {
clearTimeout(debounceTimer);
debounceTimer = setTimeout(autoUpdate, 220);
};
const analyze = async () => {
if (locked) return;
const text = textEl.value ?? '';
const model = modelSelect.value || 'llama3.2';
updateBasics();
if (isBlank(text)) {
setError('');
setStatus('', 'idle');
clearCount();
clearMetrics();
clearHeatmap();
clearResponse();
return;
}
abortAuto();
setLocked(true);
setError('');
setStatus('busy', 'analyzing…');
try {
const countRes = await fetch('/count', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ model, text }),
});
const countJson = await countRes.json();
if (!countRes.ok) throw new Error(countJson?.error || 'Count failed');
tokensEl.textContent = String(countJson.promptTokens);
const predict = clampInt(predictEl.value, 180, 1, 4096);
const metRes = await fetch('/metrics', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ model, text, predict }),
});
const metJson = await metRes.json();
if (!metRes.ok) throw new Error(metJson?.error || 'Metrics failed');
promptTpsEl.textContent = metJson.promptTps ? fmt(metJson.promptTps, 1) : '—';
genTpsEl.textContent = metJson.genTps ? fmt(metJson.genTps, 1) : '—';
genTokensEl.textContent = typeof metJson.genTokens === 'number' ? String(metJson.genTokens) : '—';
wallMsEl.textContent = typeof metJson.wallMs === 'number' ? (metJson.wallMs.toFixed(0) + ' ms') : '—';
if (typeof metJson.promptTokens === 'number') {
tokensEl.textContent = String(metJson.promptTokens);
}
clearHeatmap();
const maxSteps = clampInt(maxStepsEl.value, 120, 1, 300);
const hmRes = await fetch('/heatmap', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ model, text, maxSteps }),
});
const hmJson = await hmRes.json();
if (!hmRes.ok) throw new Error(hmJson?.error || 'Heatmap failed');
renderHeatmap(hmJson);
const genRes = await fetch('/generate', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ model, text, predict }),
});
const genJson = await genRes.json();
if (!genRes.ok) throw new Error(genJson?.error || 'Generate failed');
renderResponse(genJson);
setStatus('ok', 'ok');
} catch (e) {
setStatus('bad', 'error');
setError(String(e?.message ?? e));
} finally {
setLocked(false);
updateBasics();
}
};
textEl.addEventListener('input', () => {
updateBasics();
scheduleAuto();
});
modelSelect.addEventListener('change', () => {
modelLabel.textContent = modelSelect.value || 'llama3.2';
clearHeatmap();
clearResponse();
scheduleAuto();
});
analyzeBtn.addEventListener('click', analyze);
(async () => {
setStatus('', 'idle');
setLocked(false);
setError('');
clearHeatmap();
clearResponse();
clearMetrics();
clearCount();
textEl.value = 'Tokens are not words.';
await loadModels();
updateBasics();
if (!isBlank(textEl.value)) {
autoUpdate();
}
})();
</script>
</body>
</html>`;
const server = http.createServer(async (req, res) => {
const u = new URL(req.url ?? '/', `http://${HOST}:${PORT}`);
if (req.method === 'GET' && u.pathname === '/') {
return send(res, 200, html, 'text/html; charset=utf-8');
}
if (req.method === 'GET' && u.pathname === '/models') {
try {
const tags = await getJSON(endpoints.tags);
const models = Array.isArray(tags?.models)
? tags.models.map(m => m?.name).filter(Boolean)
: [];
return sendJSON(res, 200, { models });
} catch {
return sendJSON(res, 200, { models: [] });
}
}
if (req.method === 'POST' && u.pathname === '/count') {
try {
const body = await readJSON(req);
const model = String(body?.model ?? 'llama3.2');
const text = String(body?.text ?? '');
if (!text.trim()) return sendJSON(res, 200, { promptTokens: 0 });
const promptTokens = await countPromptTokens(model, text);
return sendJSON(res, 200, { promptTokens });
} catch (e) {
return sendJSON(res, 500, { error: safeError(e) });
}
}
if (req.method === 'POST' && u.pathname === '/metrics') {
try {
const body = await readJSON(req);
const model = String(body?.model ?? 'llama3.2');
const text = String(body?.text ?? '');
const predict = clampInt(body?.predict, 128, 1, 4096);
if (!text.trim()) {
return sendJSON(res, 200, {
wallMs: 0,
promptTokens: 0,
genTokens: 0,
promptTps: null,
genTps: null,
raw: {},
});
}
const m = await measureMetrics(model, text, predict);
return sendJSON(res, 200, m);
} catch (e) {
return sendJSON(res, 500, { error: safeError(e) });
}
}
if (req.method === 'POST' && u.pathname === '/heatmap') {
try {
const body = await readJSON(req);
const model = String(body?.model ?? 'llama3.2');
const text = String(body?.text ?? '');
const maxSteps = clampInt(body?.maxSteps, 120, 1, 300);
if (!text.trim()) {
return sendJSON(res, 200, {
model,
textLen: 0,
totalTokens: 0,
limit: 0,
segments: [],
remainder: '',
});
}
const hm = await buildHeatmap(model, text, maxSteps);
return sendJSON(res, 200, hm);
} catch (e) {
return sendJSON(res, 500, { error: safeError(e) });
}
}
if (req.method === 'POST' && u.pathname === '/generate') {
try {
const body = await readJSON(req);
const model = String(body?.model ?? 'llama3.2');
const text = String(body?.text ?? '');
const predict = clampInt(body?.predict, 180, 1, 4096);
if (!text.trim()) {
return sendJSON(res, 200, {
wallMs: 0,
promptTokens: 0,
genTokens: 0,
promptTps: null,
genTps: null,
response: '',
raw: {},
});
}
const out = await generateResponse(model, text, predict);
return sendJSON(res, 200, out);
} catch (e) {
return sendJSON(res, 500, { error: safeError(e) });
}
}
send(res, 404, 'not found');
});
server.listen(PORT, HOST, () => {
console.log(`Tokenizer Playground: http://${HOST}:${PORT}`);
console.log(`Using Ollama at: ${OLLAMA}`);
});
Run it:
node tokenizer-playground-server.mjs
Then open:
http://localhost:8787
This page is intentionally minimal, because the learning is in the feedback loop. As you type, your prompt token count updates, and you start noticing the patterns that matter in production. Long URLs spike tokens faster than you expect, repeated JSON keys quietly add up, and whitespace sometimes costs less than your instincts would suggest. Once you’ve watched token counts move under your cursor, the phrase “prompt budget” stops sounding theoretical. The transition from this toy page to real agent tooling is basically: add guardrails, add caching, and wire it into your editor.
Practical prompt design: formatting that reduces token waste
Token efficiency is not about being terse; it’s about being deliberate. Repeated boilerplate instructions, long system preambles copied into every request, and verbose JSON keys can quietly burn your context window while adding little value. A small amount of structure is good, because it makes outputs stable and parsing reliable, but there is a tipping point where structure becomes overhead. The most common token-waste pattern is accidental repetition: restating the same constraints three different ways “just to be safe.” Models do not become three times safer; your budget just gets three times smaller.
The simplest practical rule is to treat prompts like you treat payloads: keep the semantic content high and the wrapper low. Prefer short, consistent labels instead of long prose repeated across requests. Push static instructions into a single reusable template in your code rather than pasting them into every prompt by hand. When you must include large text (logs, files, transcripts), summarize or chunk it instead of dumping it raw. Tokens are expensive primarily because they compete with output and latency, so every wasted token is paid twice: once in context space and again in evaluation time.
Production notes: truncation, chunking rules, and prompt budgets
In production, tokenization stops being an educational curiosity and becomes an operational constraint. Every model has a maximum context window, and your prompt plus your desired output must fit inside it. If you do not budget explicitly, truncation will happen implicitly, usually at the worst possible moment. That truncation might cut off the end of your user input, the tail of a file, or the very instruction that makes the output safe and correct. The fix is not “trust the model”; the fix is “measure tokens and enforce budgets.” Your future agent mode depends on this.
Chunking is where the boring engineering pays off. When you need to feed large inputs (docs, code, logs), split them into chunks that preserve boundaries humans care about: files, functions, sections, paragraphs, or semantic units from a parser. Keep a strict per-chunk token budget so the model’s attention does not get diluted across too much noise. Reserve a fixed portion of the window for the model’s output, because “we’ll just see what happens” is how you end up with a half-finished response and no room to continue. Tokens are not just a cost metric, they are your control surface for reliability.
Four quick runs that expose tokenizer costs
Try these four inputs with the CLI and you’ll learn more than a dozen vague blog posts can teach. Start with a plain-English prompt to establish a baseline, then hit the tokenizer with a URL-heavy string to surface the “URL tax,” then feed it a chunk of JSON with repeated keys to watch structural overhead accumulate. Finally, run a short generation using the same baseline prompt so you can connect input tokens to output tokens and see how fast your budget burns when you actually produce text. You are not hunting for a magical “correct” number—token counts vary by tokenizer and model. You’re hunting for relative behavior inside your own runtime. When the URL version spikes, that’s the URL tax. When the JSON grows faster than your intuition, that’s structural overhead. When heatmap boundaries get weird around punctuation or Unicode, that’s the tokenizer doing what it was trained to do, not what you wish it would do. When generation chews through tokens, that’s the real cost of “just one more paragraph.”
Here are four commands that work well as a first pass:
node token-inspector.mjs count --model llama3.2 \
--text "Write a one-paragraph explanation of tokenization."
node token-inspector.mjs count --model llama3.2 \
--text "Summarize https://example.com/some/really/long/path?with=query&and=parameters"
node token-inspector.mjs heatmap --model llama3.2 \
--text '{"task":"summarize","constraints":{"style":"concise","style":"concise","style":"concise"}}'
node token-inspector.mjs generate --model llama3.2 \
--text "Write a one-paragraph explanation of tokenization." --predict 220
The “answer” you want to walk away with is not a token count; it’s a habit. Measure tokens whenever you change a prompt format, and treat token budgets like you treat memory budgets in systems code. Small differences compound when prompts are repeated thousands of times, and they compound brutally when you start building agents that stuff plans, context, diffs, and tool outputs into a single call. Treat tokens like RAM: you don’t “hope” you have enough; you measure, budget, and enforce limits.
Write Prompts Like Specs
You don’t need to memorize token math. You need to build the reflex that tokens are a real constraint, like RAM or bandwidth, and that your prompt is the thing spending it. The practical win is simple: stop writing prompts like essays and start writing them like specs. Put the goal first, add only the minimum context needed to make the goal unambiguous, and be explicit about the shape of the output you want. When you’re tempted to paste “just one more” chunk of logs or code, pause and ask: “Is this required, or am I trying to outsource thinking?” Tokens punish ambiguity and reward structure. A smaller, clearer prompt buys you more room for the model to reason, more room for tool output, and less room for the conversation to get truncated into nonsense. If you can measure tokens, you can control them; and once you can control them, you stop guessing and start building.
Sources
[1] Ollama API Reference — Generate endpoint (response fields include prompt_eval_count/eval_count and durations)
[3] Sennrich, Haddow, Birch (2015). Neural Machine Translation of Rare Words with Subword Units (BPE in NMT)
[4] Kudo, Richardson (2018). SentencePiece: A simple and language independent subword tokenizer and detokenizer (Unigram/SentencePiece)
[6] tiktoken (OpenAI) — fast BPE tokenizer implementation (useful conceptual reference for byte-level BPE behavior)
[7] Ollama FAQ (GitHub) — environment variables and origin settings (CORS-related behavior may be configured via OLLAMA_ORIGINS)
[8] Ollama PR Expose tokenization and detokenization via HTTP API endpoints (work-in-progress; shows future direction)

About Joshua Morris
Joshua is a software engineer focused on building practical systems and explaining complex ideas clearly.